Hello,
I know nothing about the book, so I can tell you nothing about it. It would be probably best to start at Wikipedia; they give you the definition at least.
Let's say we have a random variable X that can be one of the following values: x_1, ..., x_n. Then, entropy of X (in Shannon sense) is defined as:
Code: Select allH(X) = - sum_{i=1}^{n} (p_i * log_{2} p_i
where p_i is a probability that X = x_i.
This is kind of a definition, so let's see how to use it in practice; how to compute an entropy of a file, for example. In that case, we can define the X as a random variable modeling one byte of file contents – X \elem {0, ..., 255}. Then, p_i would be
where
count(i)[/code] is a number of times a byte with value []b[i/b] is present within the file.
See this for more details:
http://stackoverflow.com/questions/9904 ... -of-a-file
Let's have a 1 MB file that contains all zeroes. Entropy of such a file would be zero, since p_i = 1 for i = 0 and 0 for i # 0. Since log 0 is not defined for real numbers, we do not count zero probabilities into the entropy formula.
Let's again have a 1 MB file with content following an uniform distribution (meaning all byte values have the same probability). p_i = 1/256 for i \in {0, ..., 255}, so the entropy is
Code: Select allH(x) = - 256 * (1/256*log 1/256) = - log 1/256 = 8
The more random the file content looks like, the higher the entropy is.
------------------------------
You can also compute entropy for different regions of the file because entropy of the whole file is just one number that might not tell you anything interesting.
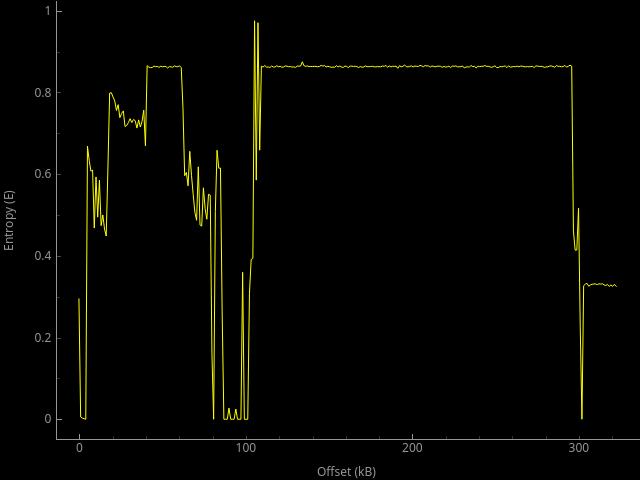
Well, now about the graph you posted.
I don't know how the graph was created so I am only guessing. It seems to me that the program got a series of packets on its input and computed entropy on byte values present on individual offsets of the packets. Then it normalized all the computed entropies, so they are between 0 and 1.
So, what I would deduce from the graph
The first part of the packets (from offset 0 to offset 100) has quite many low entropy areas which means the data on that offset do not vary too much. So, it might be some metadata informing the receiver about the packet content (maybe, there are IP and TCP/UDP headers visible too). Starting by offset 100, there is a region with quite high entropy which indicates quite random content (maybe some sort of encryption – but I would expect higher entropy for that case). At about offset 300, there is a small region with really low entropy; this looks to me as a footer metadata that are similar accross all the captured packets.
Hope this helps
Vrtule